ChatGPT, Vector Embeddings, Langchain, Vercel AI - What They Are and How They Work Together
Oct 10, 2023 by Florian

Over the last one and a half weeks, I was house-sitting my parents' house and took care of our dog Lotti, while they were on vacation.

Luckily I have access to internet and a computer here, so I used this time to work on my side project SmartDiary.co.
As a reminder, Smart Diary is a journaling app with AI integration. It uses tools like the ChatGPT API to generate diary entries from your notes, summarize your entries, and allow you to chat with the bot about your past entries.
To create this experience, I use a bunch of different AI libraries and services, including advanced techniques like vector embeddings. When you hear about all these new AI tools but don't know what each of them does, it can seem a bit overwhelming. This was the case for me just a few weeks ago. But they are actually easier to use than you would expect. In this post, I want to give you a short overview of these new AI tools, what role each of them plays, and how they work together to build cool and modern AI apps.
Table of Contents
ChatGPT API
You probably know ChatGPT already. It's one of the best currently available "large language models" that allows you to chat with an artificial intelligence. It returns responses that often can't be distinguished from that of a real human.
OpenAI's ChatGPT API is the core piece of most AI apps, including SmartDiary.co. It's a way for developers to interact with ChatGPT from inside their apps, rather than just using it over the web interface.
While the web interface is free, the API costs money. But it's really cheap—less than a cent for thousands of generated words. And it will probably get even cheaper in the future.
The ChatGPT API allows you to send a message (or a whole history of messages) to ChatGPT and get a response back. This way you can generate any kind of text and even build your own chatbots that allow a back-and-forth of messages between you and the AI.
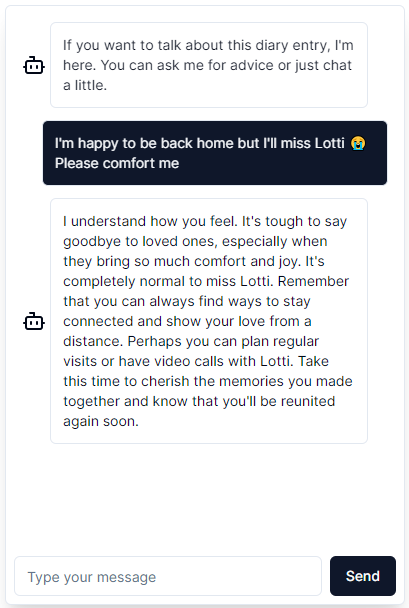
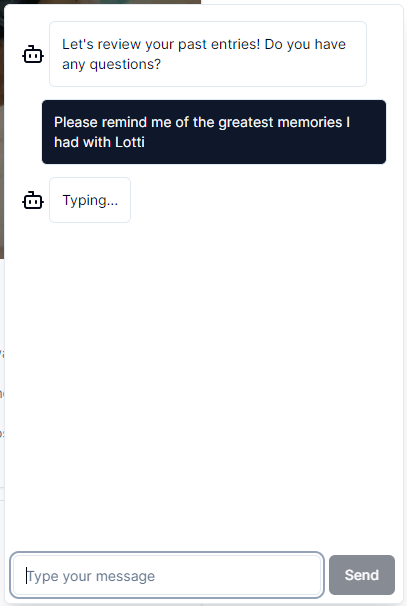
In Smart Diary, I use ChatGPT to generate diary entries from notes and to summarize entries you submitted so you can read them at a glance. I also built a chatbot with which you can talk about your past entries:
OpenAI provides different SDKs, including one in JavaScript and in Python, to easily interact with the ChatGPT API from inside your apps.
There are other alternatives to ChatGPT but it is considered the most powerful of the publicly available language models right now. Because the price is so cheap, most people use it over other alternatives.
Vector embeddings
When you interact with ChatGPT programmatically, you need to feed it some text to work with. This can be a single block of text (for example, to summarize it), or a whole history of chat messages (to generate the next message from the AI bot). ChatGPT doesn't actually have its own memory, so you always have to send it all the context it needs to understand for its next text generation. When I want to chat with the AI about past journal entries, I have to send it all the entries, and also the whole chat history, or at least the parts I need it to "memorize" right now. The ChatGPT API is priced per tokens, so the more text you send to it, the more you have to pay.
Besides getting more expensive, these models also have a limit on how much text you can send them. You can send a few thousand words to the ChatGPT API at once, but again, the more text you send, the more you pay per request.
This creates a problem. How do you build an AI app that can understand huge amounts of text, like large PDFs, books, or in the case of Smart Diary, all your journal entries? This is where vector embeddings come into play.
Vector embeddings are a machine-learning technique that transforms a text (like a query or a journal entry) into a huge array of numbers. By comparing this vector (the array of numbers) with another vector (another text that we transformed), we can find out how closely they are related to each other in their meaning. For example, "Today is Sunday and I ate ice cream" and "What did I eat on Sunday?" will generate vectors that are very close to each other. Here you can find a more detailed explanation of how vector embeddings work.
The ChatGPT API has a dedicated endpoint to generate these vectors. You can use it via the SDK just like the chat completion endpoint. You send a text to it and you get an array of numbers (a vector) back.
Then, of course, you have to store these vectors somewhere. That's where you need a vector database. Pinecone is a popular one, which I also use for Smart Diary. They have a generous free tier that is enough to build a small app with it. I take each diary entry a user writes, send it to ChatGPT to turn it into a vector, and then store it in Pinecone.
Pinecone also provides a JavaScript SDK that makes inserting into and querying the vector database easy. Earlier I explained that we can find the similarity between two vectors by how close they are to each other. For this, the Pinecone SDK provides a simple query method to which you can pass a vectorized text and compare it with the vectors that we already store in the database. Let's take a look at an example:
const query = "On what day did I visit grandma?";
const embeddingResponse = await openai.embeddings.create({
user: user.id,
model: "text-embedding-ada-002",
input: query,
});
const embedding = embeddingResponse.data[0].embedding;
const vectorQueryResponse = await diaryEntriesIndex.query({
vector: embedding,
topK: 30,
filter: {
userId: user.id,
},
});
const entries = await prisma.diaryEntry.findMany({
where: {
id: {
in: vectorQueryResponse.matches?.map((match) => match.id),
},
},
select: {
date: true,
summary: true,
},
});
In the code above, we take a query string and turn it into a vector embedding via OpenAI's embeddings API. We then pass this vector to Pinecone's query function to compare it with the vectors already in our database. In the case of Smart Diary, those are the diary entries of the user which also have been vectorized via OpenAI earlier when the user created them. The diaryEntriesIndex we call query on is simply a reference to our database (this is described in Pinecone's documentation). The number we pass to topK defines how many results we get back, and filter should be self-explaining (only return diary entries for this particular user). As you can see, the syntax is just as simple as any other database SDK. And what we get back are the 30 vectors (= journal entries) that are closest to our query.
Now that we found the most relevant documents for the user's query in our database, we can simply pass them to ChatGPT's completion endpoint to generate an AI response:
const response = await openai.chat.completions.create({
model: "gpt-3.5-turbo",
user: user.id,
messages: [
{
role: "system",
content:
"You are an intelligent diary. " +
"You answer the user's question based on their previous entries. " +
"The previous entries are:\n" +
entries
.map(
(entry) =>
`Date: ${entry.date.toDateString()}\nSummary:\n${entry.summary}`
)
.join("\n\n"),
},
{ role: "user", content: query },
],
});
What we get back is an AI text response by ChatGPT. In the actual code of Smart Diary, I send the whole chat history to ChatGPT. But the rest is the same.
To summarize: Vector embeddings turn text into an array of numbers, which represents a point in a space with many dimensions (over a thousand of them). By comparing how close one point is to another point, we can find out how closely related two texts are in their meaning. This allows us to find only relevant documents which we can then feed into ChatGPT's limited input window.
If you want to see this in action, check out my app SmartDiary.co. You can write journal entries and then chat with the AI about them. The AI will answer your questions by searching for the relevant entries in your journal and then "reading" them. It has become a super useful companion for myself.
The ChatGPT API and vector embeddings are the most important tools to build powerful AI apps. Make sure to learn them. As I've shown, they are not hard to use.
There are also two other tools that I've played around with these last few days but didn't end up using in my project. They are Langchain and Vercel's AI SDK. Let's briefly talk about them.
Langchain
Langchain itself is not another AI service, but a library that helps you work with and combine other AI tools, such as OpenAI and Pinecone. It's available for Python and JavaScript
Since OpenAI and Pinecone both have great SDKs, I didn't see a need for Langchain in my project. On the contrary, I actually found that it rather complicated my code with unnecessary abstractions. Everything that Langchain could "help" me do, like managing chat histories or parsing data out of ChatGPT's responses, I could easily do myself. Thus I removed it.
Maybe Langchain shines when you start building very complex AI apps that combine many different prompts and even different language models. But I didn't need it for Smart Diary.
Vercel AI SDK
SmartDiary.co is built with Next.js, my favorite full-stack framework for building amazing SEO-optimized React apps. Vercel, the creators of Next.js, have released another AI SDK that you can install via npm install ai (how did they manage to get this package name?).
Just like Langchain, this library helps you work with other existing AI tools. The most useful feature it provides is an easy way to stream your AI responses to the front end. Streaming means that you don't have to wait until the whole ChatGPT API response has been generated. Instead, you can start sending text, word by word (= streaming) to the front end and display it there quicker. The ChatGPT API provides an option to stream responses like this, and Vercel's AI SDK helps you consume these streams in your app. This creates an experience that looks like what you see on ChatGPT's web interface. It's not just meant to look cool, the words are actually generated one after another like this.
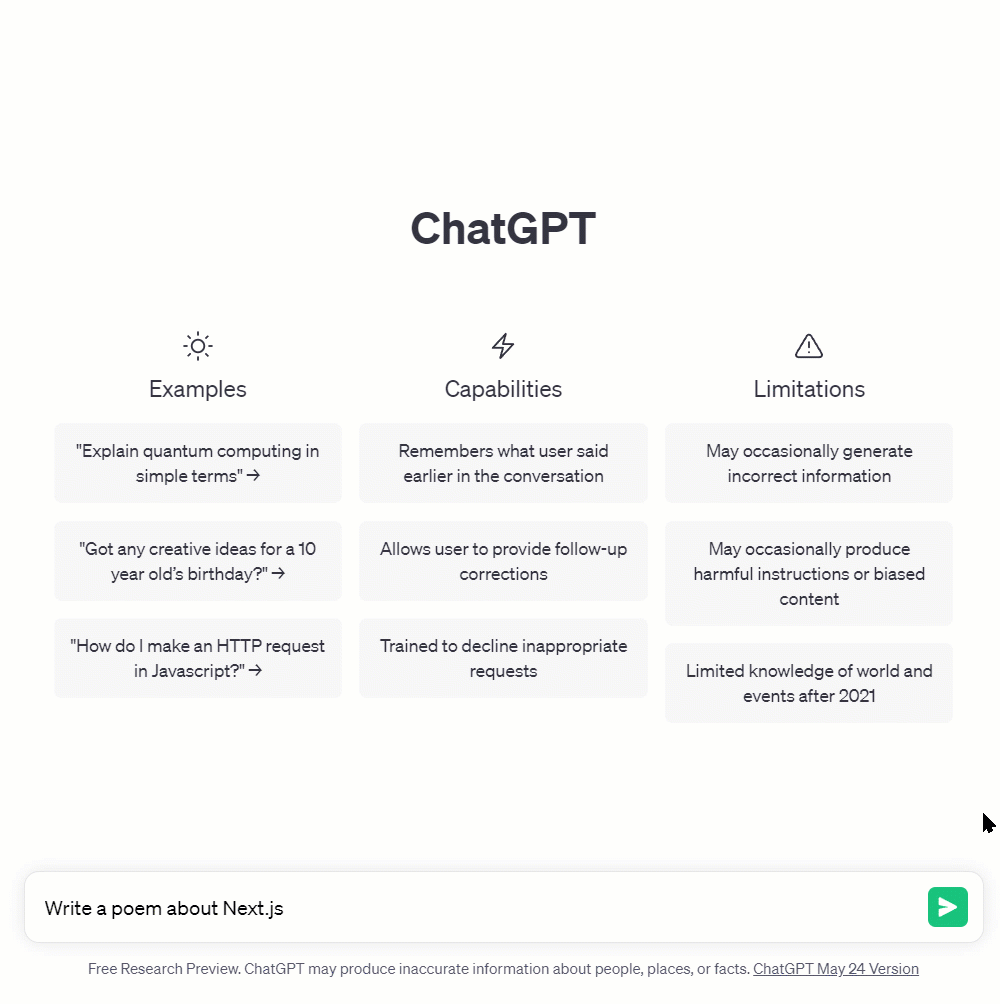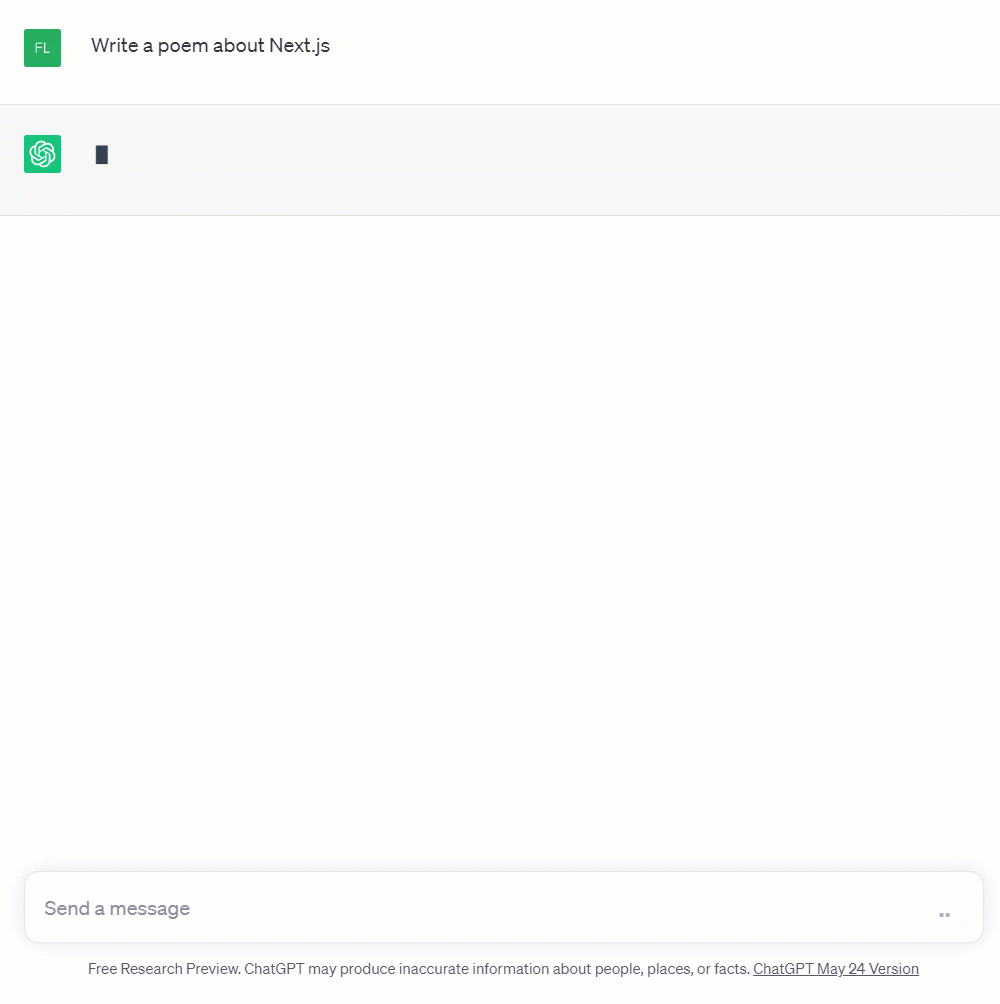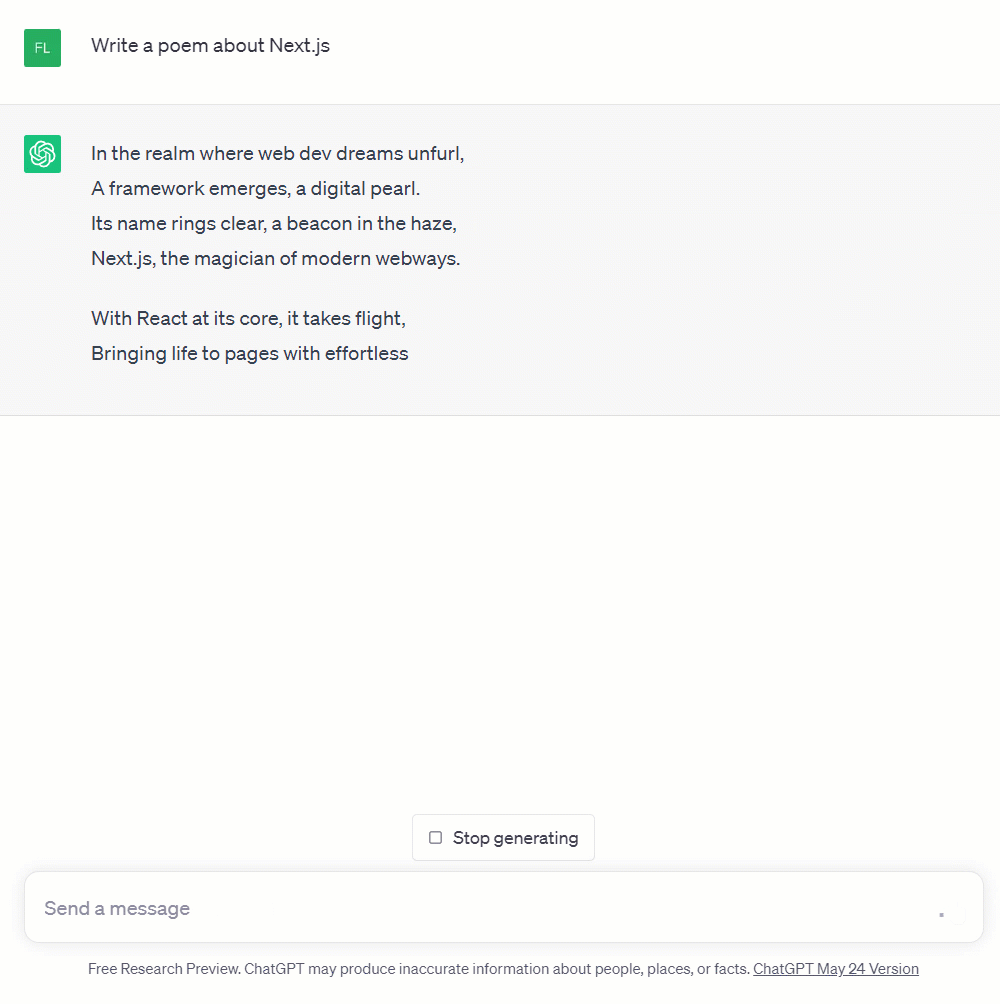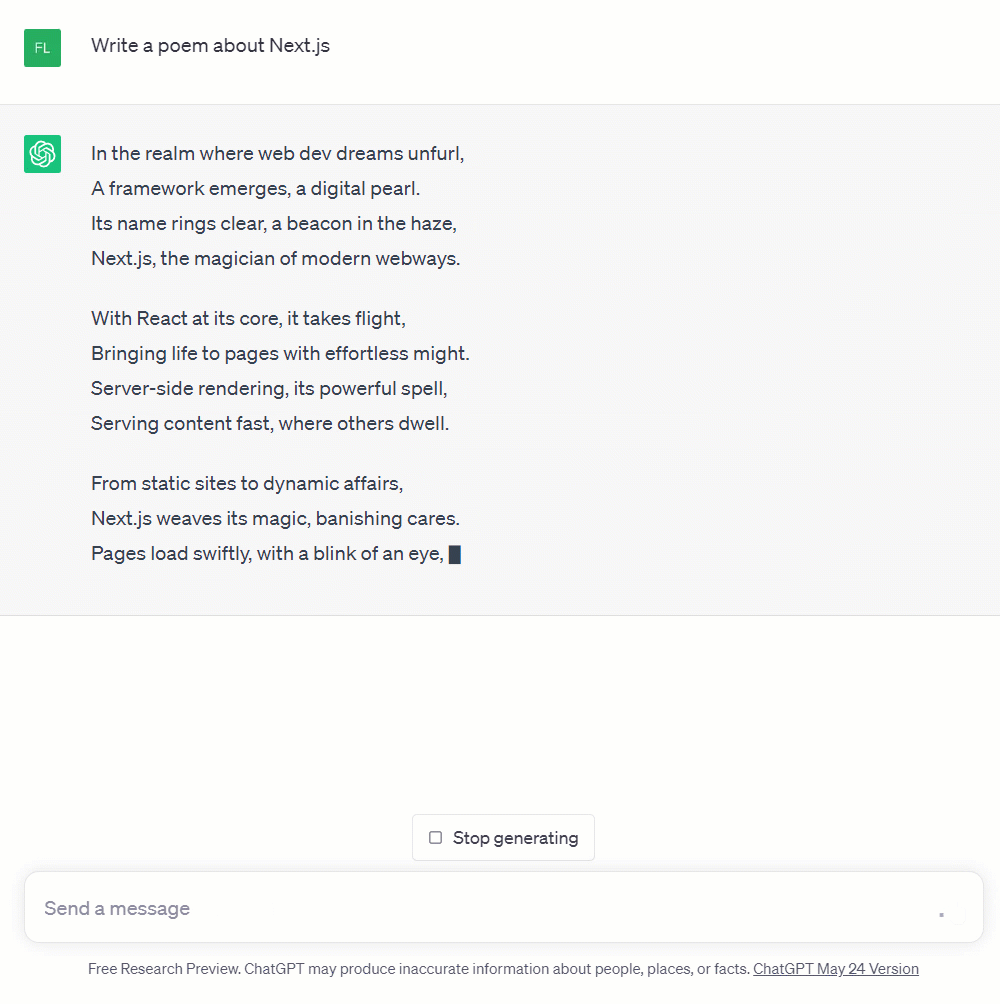
The Vercel AI SDK provides a simple response wrapper that you can return from a route handler:
export async function POST(req: Request) {
const { messages } = await req.json();
// Create a chat completion using OpenAI
const response = await openai.chat.completions.create({
model: 'gpt-3.5-turbo',
stream: true,
messages,
});
// Transform the response into a readable stream
const stream = OpenAIStream(response);
// Return a StreamingTextResponse, which can be consumed by the client
return new StreamingTextResponse(stream);
}
You can learn more in the documentation.
Streaming is great, but I don't use it in Smart Diary because it's currently not supported in server actions. I use server actions for almost all my app's server endpoints and I don't want to restructure my app to use route handlers instead. So I ignore streaming and instead show a loading indicator that says "Typing..." while we are waiting for the ChatGPT response. I think that's absolutely fine.
The Vercel AI SDK also provides code to more easily manage chat histories between a user and a bot. However, I didn't see the need for that in Smart Diary, because I already built that functionality myself.
Thus, just like Langchain, I ended up not using the Vercel AI SDK in my app. But if you want to implement streaming AI responses, it will help you with that. However, the library is not essential for building powerful AI apps, and, of course, you can also handle the streaming part yourself.
There are more providers of language models, vector databases, and other AI tools out there. If you're just starting out with AI, I recommend starting with ChatGPT and Pinecone and building something with it. Also, make sure to subscribe to my YouTube channel, because I will create more tutorials about AI and Next.js in the future.
Happy coding!
Florian
Get my free email newsletter
I send my best web dev tips to my email subscribers.
Sign up to stay ahead of the curve.


